Kindle Clippings to HTML
Developed: Solo Language: Python
An app made using the tkinter library which takes a Kindle clippings text file and converts it into a nicely formatted html document. This text can then easily be parsed by a lookup dictionary like Yomichan to make Anki flashcards.
GUI created using tkinter
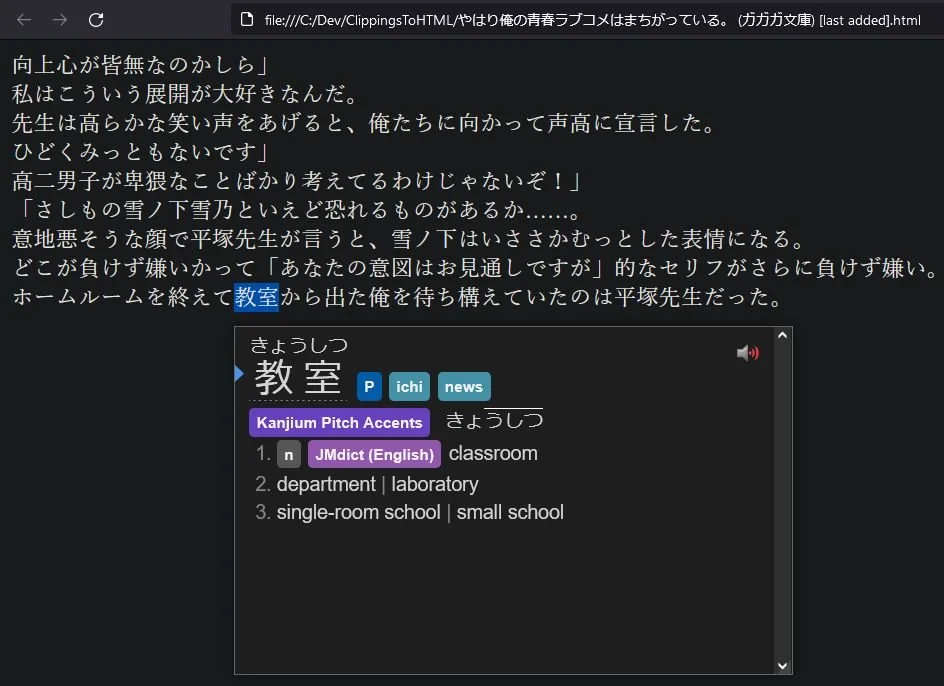
Resulting HTML document being parsed with Yomichan
This project was created to easily create Anki flashcards from Amazon Kindle clippings using Yomichan.
The program takes Amazon Kindle clippings formatted in KindleMate to a txt format and converts them into a neatly formatted HTML file. The text can then easily be parsed using browser extensions such as Yomichan. On first run, produces a single html file. On subsequent runs, user can tick checkbox to produce two html files. The first html file (same name as source file) will contain all the clippings that have been processed until then. The second html file (source file name + [last added]) will only contain the clippings which were added during the latest successful conversion. This allows the user to keep a databank of all sentences converted, while also easily knowing which sentences are yet to be parsed with Yomichan to make Anki cards.
Github repository can be found here.
Text Ripper
Developed: Solo Language: Python
An app which extracts the html source of a series of websites, parses the text, finds the desired section, removes any html tags and finally neatly formats all of the texts into one large file. Used to download multiple chapters of a light novel which are on seperate websites and combine them all into one file.
The purpose of this project was to create an application which parses text from multiple websites and produced a neatly formatted text file containing the desired text. This text can then be transferred onto a Kindle and read as an ebook. In this project, I compiled the text from 266 chapters of お隣の天使様 into a single text file, with seperate sections for each chapter. The source text can be found here.
GitHub repository for this project can be found here.
List of hyperlinks to chapters of the light novel being parsed